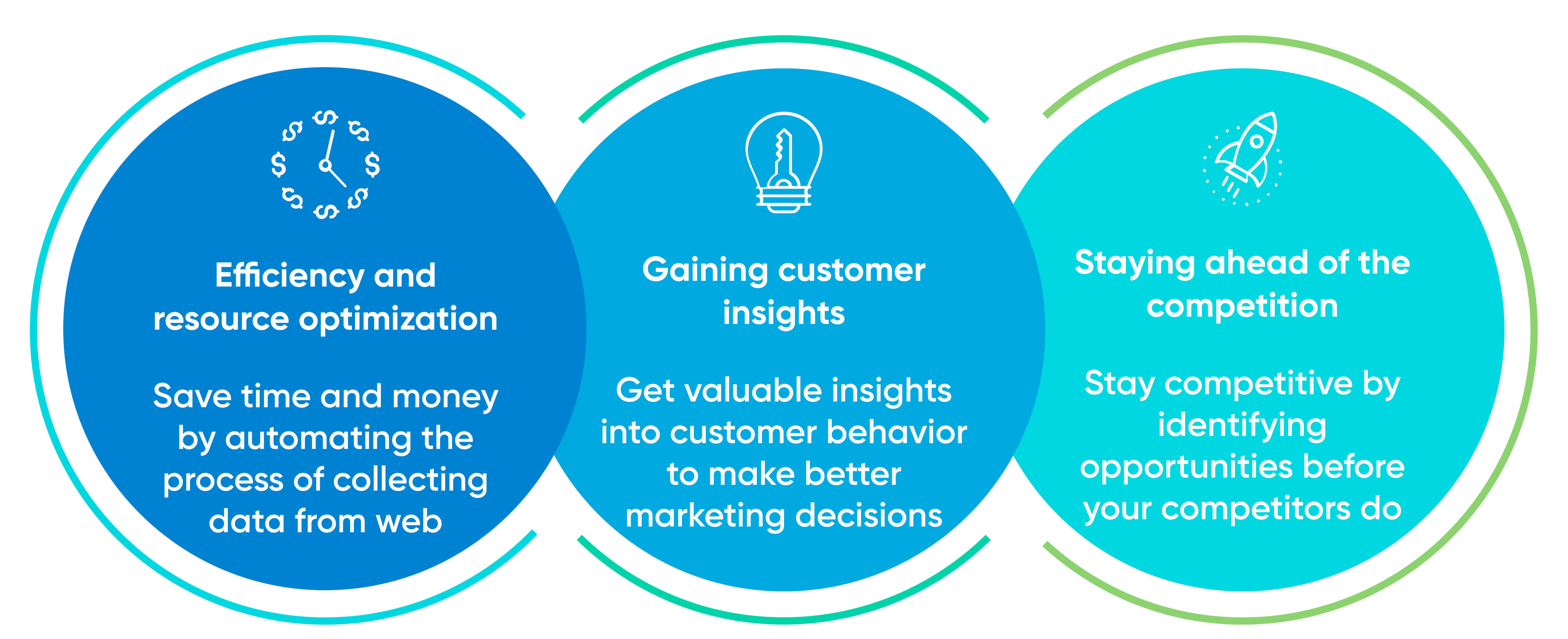
Data Scraping Wikipedia Information scratching is a gratifying procedure for both little, medium, and large companies. For example, companies release the procedure to gather information perfectly and in a faster means from other websites that pertain to their sites as well. The innovation simplifies data collection and analysis by integrating with chosen documentation systems. Invite to SilentBio.com, your utmost destination for all things biotechnology and life scientific researches. Gologin.com gives a distinct digital web browser environment for each profile you produce, aiding you manage multiple Facebook scuffing jobs individually and securely. The majority of companies offer standards on just how you must scratch the internet site, which will certainly be available in the robots.txt file. These technologies will certainly allow web. scrapes to much better comprehend and navigate complicated Facebook pages, handle dynamic content, and even gain from past scraping jobs to boost future efficiency. To get going with internet scratching, you need to identify the information you wish to scratch, locate the link for the web site you are scuffing from, and utilize code to access the link and download the web page content. Python has actually come to be the go-to language for internet scratching as a result of its convenience of use and considerable collections tailored for internet scraping, like Scrapy and Beautiful Soup. Its popularity is driven by its simplicity, making it available to customers with https://rentry.co/inf54 varying degrees of shows experience.
The news media and AI: a new front in copyright law - Columbia Journalism Review
The news media and AI: a new front in copyright law.
Posted: Wed, 18 Oct 2023 15:47:42 GMT [source]
Is Data Scientific Research A Great Occupation?
The https://telegra.ph/6-Cost-Optimization-Advantages-For-Sellers-Large-And-Small-Smarter-Retail-Strategies-11-18 only new and revolutionary in 2014 tech was possibly Apple Private Gain access to Tokens. Captchas are usually still quickly understandable by third-party solutions. Most key players on the market are currently making every effort to cover the complete web data lifecycle. This describes the numerous mergers and procurements taking place throughout the years focused on structure and keeping a well-shaped internet scuffing environment.Google requests dismissal of AI data scraping class-action suit - Cointelegraph
Google requests dismissal of AI data scraping class-action suit.

Posted: Tue, 17 Oct 2023 22:41:15 GMT [source]
Using The Prospective Capabilities Of Data Scratching
Its substantial libraries and frameworks, such as Attractive Soup, Scrapy, and Requests, streamline the internet scratching process and make it possible for individuals to effectively draw out useful information from sites. Thankfully, services like Bright Data-- a detailed, award-winning collection of web scuffing devices-- can considerably enhance the web scrape advancement experience. Bright Data is not just another scuffing library yet a complete giant of functionalities, tailored web scuffing themes and proxies. Along with each various other, all elements and attributes of Bright Data permit developers to abstract the ins and outs of scraping away and concentrate on what they are really constructing. One more instance originates from the traveling industry, where numerous websites provide trips, hotels, and various other services. Yet again, prices can vary widely, and the info is frequently spread across numerous platforms.- Now the information has actually been extracted and the info can be used for whatever purpose the extractor needs.The majority of principals on the marketplace are now striving to cover the complete internet data lifecycle.Computer to user interfaces from that period were commonly simply text-based dumb terminals which were very little more than online teleprinters (such systems are still in use today, for different reasons).It features things like IP Turning, IP proxies, CAPTCHA fixing, and a lot more.